Overview
Machine learning (ML) represents the greatest turning point in computing. It’s changing the face of various industries and shaping how the general insurance and financial sector is developing.
The potential for ML is extensive and promises new levels of insight and convenience — at home, at work and at leisure.
ML uses statistical techniques to enable programs to ‘learn’ through training, rather than being programmed with rules. ML systems process training data to progressively improve performance on a task, providing results that improve with experience.
For each different task, a series of unique techniques and algorithms are used – machine learning loosely refers to this.

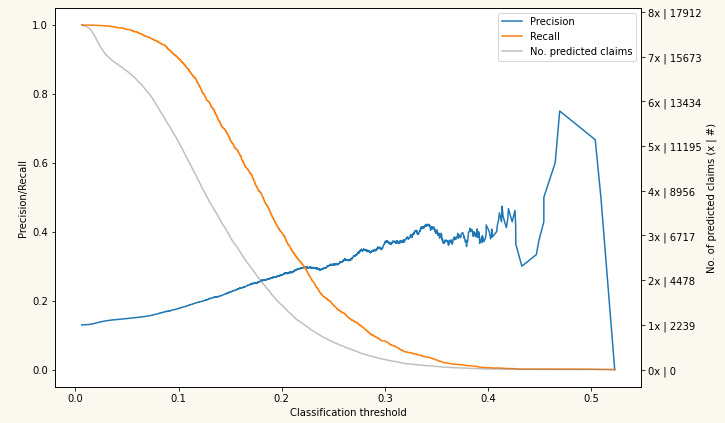
Evaluating a Claim Propensity Model
Overview
Machine learning (ML) represents the greatest turning point in computing. It’s changing the face of various industries and shaping how the general insurance and financial sector is developing.
The potential for ML is extensive and promises new levels of insight and convenience — at home, at work and at leisure.
ML uses statistical techniques to enable programs to ‘learn’ through training, rather than being programmed with rules. ML systems process training data to progressively improve performance on a task, providing results that improve with experience.
For each different task, a series of unique techniques and algorithms are used – machine learning loosely refers to this.
How does ML apply to insurance?
By sending large amounts of data to a machine learning algorithm, the machine is able to pick up on very subtle, possibly indescribable, details and trends within the data batches. It is the very being of these details and trends within the data that ultimately identifies one from the other; and computers have shown themselves to be pretty good at it.
While this probably all sounds very complex – insurance itself can also, at times, be a complex topic. But, when insurance is complemented with machine learning, powerful insights can be generated from the data produced from everyday insurance premiums. Unique ML techniques and algorithms are then used with each different insurance or risk task.
As a result of our new relationship with Open GI, we will be able to access millions upon millions of rows of data. In turn, we can then transform that data into something quite revolutionary for the general insurance industry.
How does ML apply to insurance?
By sending large amounts of data to a machine (i.e. a computer) learning algorithm, the machine is able to pick up on very subtle, possibly indescribable, details and trends within the data batches. It is the very being of these details and trends within the data that ultimately identifies one from the other; and computers have shown themselves to be pretty good at it.
While this probably all sounds very complex – insurance itself can also, at times, be a complex topic. But, when insurance is complemented with machine learning, powerful insights can be generated from the data produced from everyday insurance premiums. Unique ML techniques and algorithms are then used with each different insurance or risk task.
As a result of our new relationship with Open GI, we will be able to access millions upon millions of rows of data. In turn, we can then transform that data into something quiet revolutionary for the general insurance industry.